Du nouveau dans les triggers avec PostgreSQL 10
PostgreSQL offre des triggers qui peuvent se déclencher chaque fois
qu’une instruction est exécutée (AFTER ou BEFORE STATEMENT), ou chaque fois qu’une
ligne est affectée (AFTER ou BEFORE ROW). Jusqu’avant la version 10, seules
les fonctions associées au second type pouvaient accéder aux données
modifiées par l’instruction déclencheuse, à travers les pseudo-variables
OLD et NEW représentant l’état avant/après de la ligne affectée.
A compter de la version 10, les triggers AFTER STATEMENT peuvent avoir accès à l’ensemble des lignes modifiées, avant et après changement, à travers un nouveau genre de pseudo-variable de type table. Concrètement, la nouveauté est accessible via cette syntaxe, par exemple pour DELETE:
CREATE TRIGGER nom_trigger AFTER DELETE ON nom_table
REFERENCING OLD TABLE AS OLD
FOR EACH STATEMENT
EXECUTE PROCEDURE nom_procedure();grâce à quoi dans la fonction, OLD sera utilisable comme une table en lecture seule.
Quelle est l’utilité d’accéder globalement aux lignes changées plutôt qu’une par une?
D’abord il y a d’autres SGBDs qui utilisent cette méthode, parfois exclusivement.
Par exemple, MS-SQL server n’offre pas de déclenchement par ligne,
mais uniquement par instruction, avec les données concernées dans des
pseudo-tables inserted et deleted. Avec la version 10, il devient
plus facile de porter ces trigger vers PostgreSQL, puisqu’on peut
reproduire cette logique directement.
Il y aussi et surtout un intérêt pour les performances, dans les cas où il vaut mieux faire des opérations ensemblistes sur ces données plutôt que de les traiter ligne par ligne.
Voyons ça sur un exemple avec un benchmark tout simple.
Un schéma de test
Imaginons qu’on ait un million de documents, et une centaine de labels (tags) pour les catégoriser, avec ces structures de tables:
CREATE TABLE document (
id serial primary key,
title text,
content text
);
CREATE TABLE tag (
id serial primary key,
name text
);
CREATE TABLE doc_tag (
doc_id integer references document(id),
tag_id integer references tag(id),
unique(doc_id,tag_id)
);L’information disant, pour chaque label, à combien de documents il a été affecté s’obtient normalement par:
SELECT tag_id, count(*) FROM doc_tag GROUP BY tag_id;ou pour un seul label:
SELECT count(*) FROM doc_tag WHERE tag_id =
(SELECT tag_id FROM tag WHERE name = :nom_label);Mais quand on a beaucoup d’entrées dans doc_tag du fait qu’il y a beaucoup
de documents, ces requêtes seront lentes.
Si on sait que nos applis ont besoin de cette information instantanément, typiquement on va matérialiser et maintenir à jour un compteur permanent avec une seule ligne par label, dans une table de ce genre:
CREATE TABLE tag_count (
tag_id integer references tag(id),
cnt integer,
unique(tag_id)
);Si on part d’une table doc_tag déjà remplie on initialisera ces
compteurs avec:
INSERT INTO tag_count(tag_id,cnt)
SELECT tag_id,count(*) FROM doc_tag GROUP BY tag_id;(sans les compteurs à zéro qu’on évite pour simplifier l’exemple).
Puis va créer un trigger qui met à jour ce compteur pour toute attribution ou désattribution d’un label.
En mode FOR EACH ROW, le code pour une version 9.5+ ressemblera à ça:
CREATE FUNCTION row_update_tag_count() RETURNS trigger AS $$
BEGIN
IF TG_OP = 'INSERT' THEN
INSERT INTO tag_count(tag_id,cnt)
values (NEW.tag_id,1)
ON CONFLICT (tag_id) DO UPDATE set cnt = tag_count.cnt + 1;
ELSIF TG_OP = 'DELETE' THEN
UPDATE tag_count SET cnt = cnt - 1
WHERE tag_id = OLD.tag_id;
END IF;
RETURN NEW;
END $$ LANGUAGE plpgsql;
CREATE TRIGGER trigger1 AFTER INSERT OR DELETE on doc_tag
FOR EACH ROW
EXECUTE PROCEDURE row_update_tag_count();En mode FOR EACH STATEMENT, le code pour une version 10+ pourrait ressembler à ça:
CREATE FUNCTION set_update_tag_count() RETURNS trigger AS $$
BEGIN
IF TG_OP = 'INSERT' THEN
INSERT INTO tag_count(tag_id,cnt)
select tag_id,count(*) AS insert_count from NEW group by tag_id
ON CONFLICT (tag_id) DO UPDATE set cnt = tag_count.cnt + excluded.cnt;
ELSIF TG_OP = 'DELETE' THEN
UPDATE tag_count SET cnt = cnt - d.delete_count
FROM (select tag_id,count(*) AS delete_count from OLD group by tag_id) AS d
WHERE tag_count.tag_id = d.tag_id;
END IF;
RETURN NULL;
END
$$ LANGUAGE plpgsql;
CREATE TRIGGER trigger2 AFTER INSERT on doc_tag
REFERENCING NEW TABLE AS NEW
FOR EACH STATEMENT
EXECUTE PROCEDURE set_update_tag_count();
CREATE TRIGGER trigger3 AFTER DELETE on doc_tag
REFERENCING OLD TABLE AS OLD
FOR EACH STATEMENT
EXECUTE PROCEDURE set_update_tag_count();Ici on ne peut pas regrouper dans le même trigger INSERT ET DELETE (bien qu’associés à la même fonction) pour des questions de syntaxe, car la doc nous dit:
OLD TABLE may only be specified once, and only on a trigger which can fire on UPDATE or DELETE. NEW TABLE may only be specified once, and only on a trigger which can fire on UPDATE or INSERT
Le test
Il consiste simplement à faire un INSERT unique de 10000 tags, puis 20000, 30000 etc. jusqu’à 500000, tirés au hasard et distribués sur les documents de manière équiprobable.
Le but est de mettre en évidence la différence sur des insertions en masse entre les différents de type de trigger. On mesure le temps pris dans trois cas:
- sans trigger pour avoir un temps de base.
- avec
trigger1(FOR EACH ROW) - avec
trigger2(FOR EACH STATEMENT)
Avant chaque insertion la table doc_tag subit un TRUNCATE pour la ramener
à zéro physiquement, index inclus, et autovacuum est désactivé
pour éviter d’interférer.
Le résultat
Ce graphe montre les temps d’exécution en fonction du nombre de lignes
insérées, sur Pg10 beta3 avec la configuration entièrement par défaut.
Les lignes ne sont pas cumulées, chaque INSERT se faisant
avec dog_tag et tag_count initialement vides.
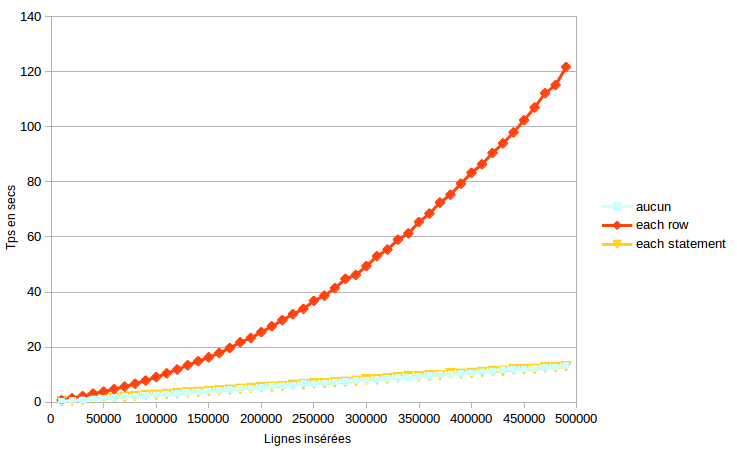
C’est sans surprise que le trigger FOR EACH ROW fait s’envoler le temps d’exécution sur une insertion en masse, par rapport au cas où il n’y a pas de trigger.
Ce qui n’est pas forcément aussi prévisible est que quel que soit le volume de l’INSERT, la différence est insignifiante entre le cas FOR EACH STATEMENT et le cas où il n’y a aucun trigger,
Autrement dit, le coût induit par trigger2 est quasiment nul, alors que
ce n’est pas du tout le cas pour trigger1.
En conclusion, une application avec ce style de comptage par trigger et de l’écriture en masse a potentiellement beaucoup à gagner, après un passage en PostgreSQL 10+, à les convertir de FOR EACH ROW en FOR EACH STATEMENT.