Aller plus loin avec ICU (Postgres 10)
Depuis la version 10, Postgres peut être configuré avec
ICU, la bibliothèque de référence
pour Unicode, afin d’utiliser ses collations (règles de tri
et de comparaison de chaînes de caractères) via des clauses COLLATE.
Pour ce faire, les collations ICU pour la plupart des langues/pays
sont automatiquement créées au moment d’initdb (on les trouvera
dans pg_catalog.pg_collation), et d’autres peuvent être ajoutées
plus tard avec CREATE COLLATION.
Au-delà du support des collations, ICU fournit d’autres services relatifs aux locales et à la gestion du texte multilingue, suivant les recommandations d’Unicode.
A partir du moment où nos binaires Postgres sont liées à ICU (la plupart le sont parce que les installeurs les plus importants comme Apt, Rpm ou Rdb l’incluent d’office), pourquoi ne pas chercher à bénéficier de tous ces services à travers SQL?
C’est le but de icu_ext,
une extension en C implémentant des interfaces SQL aux fonctions d’ICU.
Actuellement elle comprend une vingtaine de fonctions permettant
d’inspecter les locales et les collations, de découper du texte,
de comparer et trier les chaînes de caractères, d’évaluer
l’utilisation trompeuse de caractères Unicode (spoofing),
d’épeler des nombres et de faire des conversions entre systèmes
d’écriture (translitération).
Avant de voir les fonctions de comparaison et tri, faisons un point sur ce qu’amène l’intégration d’ICU dans Postgres.
Les bénéfices d’ICU par rapport aux collations du système
-
Versionnage:
pg_collation.collversioncontient le numéro de version de chaque collation au moment de sa création, et si au cours de l’exécution elle ne correspond plus à celle de la bibliothèque ICU (typiquement après un upgrade), un avertissement est émis, invitant l’utilisateur à reconstuire les index potentiellement affectés et à enregistrer la nouvelle version de la collation dans le catalogue. -
Cohérence inter-systèmes: une même collation ICU trie de la même façon entre systèmes d’exploitation différents, ce qui n’est pas le cas avec les “libc” (bibliothèque C de base sur laquelle s’appuie tous les programmes du système). Par example avec un même
lc_collateàen_US.UTF-8a un comportement différent entre Linux and FreeBSD: des couples de chaînes de caractères aussi simples que0102and"0102"se retrouvent ordonnés de manières opposées. C’est une des raisons pour lesquelles il ne faut pas répliquer une instance sur un serveur secondaire avec un système d’exploitation différent du primaire. -
Vitesse d’indexation: Postgres utilise les clefs abrégées (abbreviated keys) quand c’est possible (également appelées sort keys dans la terminologie ICU), parce qu’elles peuvent vraiment accélérer l’indexation. Mais comme le support de cette fonctionnalité via libc (
strxfrm) s’est avéré buggé dans plusieurs systèmes dont Linux pour certaines locales, elle est seulement activée pour les collations ICU. -
Comparaison de chaînes paramétrique: Avec la libc, il y a typiquement une association figée entre la locale et la collation: par exemple
fr_CA.UTF-8compare les chaînes avec les règles linguistiques du français tel qu’écrit au Canada, mais sans possibilité de personnalisation ou de contrôle supplémentaire. Avec ICU, les collations acceptent un bon nombre de paramètre qui offre des possibilités au-delà de la spécification de la langue et du pays, comme montré dans la démo online de collationnement ICU, ou dans le billet de Peter Eisentraut “More robust collations with ICU support in PostgreSQL 10” annonçant l’intégration ICU l’année dernière, ou encore dans “What users can do with custom ICU collations in Postgres 10” (fil de discussion dans pgsql-hackers).
Ce que Postgres ne peut pas (encore) faire avec les collations ICU
Malheureusement un problème empêche d’utiliser les comparaisons avancées à leur plein potentiel: l’infrastructure actuelle des opérateurs de comparaison dans Postgres ne peut pas gérer le fait que des chaînes soient égales alors qu’elles ne sont pas équivalentes en comparaison octet par octet. Pour s’assurer que cette contrainte est bien respectée, dès que des chaînes sont considérées comme égales par un comparateur linguistique (avec une fonction de la famille de strcoll), Postgres cherche à les départager par comparaison binaire, via ce qu’on va appeler en anglais le strcmp tie-breaker; le résultat généré par le comparateur ICU (ou celui de libc d’ailleurs) est alors éliminé en faveur du résultat de la comparaison binaire.
Par exemple, on peut créer cette collation:
CREATE COLLATION "fr-ci" (
locale = 'fr-u-ks-level1', /* ou 'fr@colStrength=primary' */
provider = 'icu'
);ks-level1 ici signifie primary collation strength.
Il faut savoir que cette syntaxe avec les paramètres au format
BCP-47
ne fonctionne pas (sans pour autant émettre d’erreur) avec ICU 53 ou plus ancien.
Lorsqu’on n’est pas sûr de la syntaxe d’une collation,
elle peut être passée à icu_collation_attributes() pour vérifier
comment ICU l’analyse, comme montré par un exemple un peu plus loin
dans ce billet.
Quoiqu’il en soit, il y cinq niveaux de force de comparaison, le niveau primaire ne considérant que les caractères de base, c’est-à-dire qu’il ignore les différences engendrées par les accents et la casse (majucule ou minuscule).
Le principe de départager les chaînes égales via une comparaison binaire fait que l’égalité suivante, par exemple, ne va pas être satisfaite, contrairement à ce qu’on pourrait attendre:
=# SELECT 'Eté' = 'été' COLLATE "fr-ci" as equality;
equality
----------
fPeut-être (espérons) que dans le futur, Postgres pourra faire
fonctionner complètement ces collations indépendante de la casse
et autres, mais en attendant, il est possible de contourner
ce problème avec des fonctions de icu_ext. Voyons comment.
Comparer des chaînes avec des fonctions de icu_ext
La fontion principale est:
icu_compare(string1 text, string2 text [, collator text]).
Elle renvoie le résultat de ucol_strcoll[UTF8](), comparant
string1 et string2 avec collator qui est la collation ICU.
C’est un entier signé, négatif si string1 < string2, zéro if string =
string2, et positif si string1 > string2.
Quand le 3ème argument collator est présent, ce n’est pas le nom d’une
collation de la base de données déclarée avec
CREATE COLLATION, mais la valeur qui serait passée
dans le paramètre locale ou lc_collate, si on devait
instancier cette collation. En d’autres termes, c’est un locale ID
au sens d’ICU, indépendamment de Postgres
(oui, ICU utilise le terme “ID” pour désigner une chaîne de caractères
dont le contenu est plus ou moins construit par aggrégation de paramètres).
Quand l’argument collator n’est pas spécifié, c’est la collation associée
à string1 et string2 qui est utilisée pour la comparaison.
Ca doit être une collation ICU et ça doit être la même pour les
deux arguments, ou la fonction sortira une erreur.
Cette forme avec deux arguments est significativement plus rapide
du fait que Postgres garde ses collations ouvertes (au sens de
ucol_open()/ucol_close()) pour la durée de la session,
tandis que l’autre forme avec l’argument collator explicite ouvre
et ferme la collation ICU à chaque appel.
Pour revenir à l’exemple précédent, cette fois on peut constater l’égalité des chaînes de caractère sous le régime de l’insensibilité à la casse et aux accents:
=# SELECT icu_compare('Eté', 'été', 'fr-u-ks-level1');
icu_compare
-------------
0Les comparaisons sensibles à la casse mais insensibles aux accents sont aussi possibles:
=# SELECT icu_compare('abécédaire','abecedaire','fr-u-ks-level1-kc'),
icu_compare('Abécédaire','abecedaire','fr-u-ks-level1-kc');
icu_compare | icu_compare
-------------+-------------
0 | 1Autre exemple, cette fois avec une collation Postgres implicite:
=# CREATE COLLATION mycoll (locale='fr-u-ks-level1', provider='icu');
CREATE COLLATION
=# CREATE TABLE books (id int, title text COLLATE "mycoll");
CREATE TABLE
=# insert into books values(1, 'C''est l''été');
INSERT 0 1
=# select id,title from books where icu_compare (title, 'c''est l''ete') = 0; id | title
----+-------------
1 | C'est l'été
La gestion des caractères diacritiques combinatoires
Avec Unicode, les lettres accentuées peuvent être écrites sous une forme composée ou décomposée, cette dernière signifiant qu’il y a une lettre sans accent suivi d’un caractère d’accentuation faisant partie du bloc des diacritiques combinatoires.
Les deux formes avec décomposition, NFD or NFKD
ne sont pas fréquemment utilisées dans les documents UTF-8, mais elles
sont parfaitement valides et acceptées par Postgres.
Sur le plan sémantique, 'à' est supposément équivalent à
E'a\u0300'. En tout cas, le collationnement ICU semble les considérer comme
égaux, y compris sous le niveau de comparaison le plus strict:
=# CREATE COLLATION "en-identic" (provider='icu', locale='en-u-ks-identic');
CREATE COLLATION
=# SELECT icu_compare('à', E'a\u0300', 'en-u-ks-identic'),
'à' = E'a\u0300' COLLATE "en-identic" AS "equal_op";
icu_compare | equal_op
-------------+----------
0 | f(à nouveau, l’opérateur d’égalité de Postgres donne un résultat différent à cause de la comparaison binaire qui départage les deux arguments. C’est précisement pour contourner ça qu’on utilise une fonction au lieu de l’opérateur d’égalité).
Par ailleurs, les caractères combinatoires ne concernent pas seulement les accents, certains servent aussi à réaliser des effets sur le texte comme l’effet barré ou le soulignement. Voyons un exemple dans psql, tel qu’affiché dans un terminal gnome.
La requête de la capture d’écran ci-dessous prend le texte litéral ‘Hello’, insère les caractères combinatoires de U+0330 à U+0338 après chaque caractère, renvoie la chaîne résultante, ainsi que les résultats des comparaisons linguisitique primaire et secondaire avec le texte de départ.
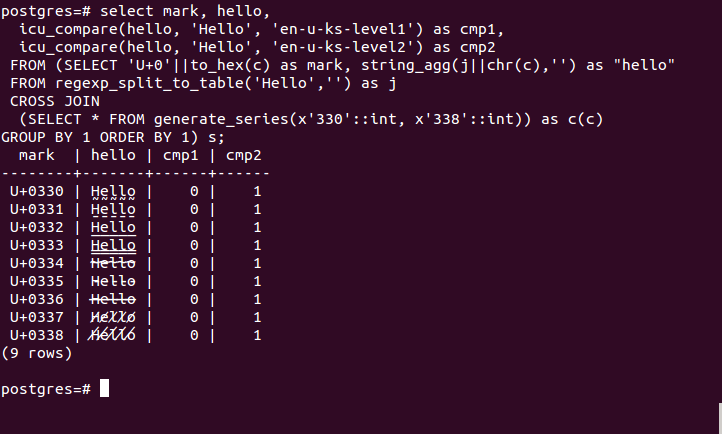
En général, les fonctions ICU prennent en compte les caractères combinatoires à chaque fois que ça a du sens, alors que les fonctions de Postgres hors ICU (celles des expressions régulières par exemple) considèrent que le caractère combinatoire est un point de code comme un autre.
Tri et regroupements
Les clauses ORDER BY et GROUP BY ne sont pas conçues pour fonctionner avec des fonctions à deux arguments, mais avec des fonctions à un seul argument qui le transforment en quelque chose d’autre.
Pour trier ou regrouper des résultats d’après les règles linguistiques avancées, icu_ext expose une fonction qui convertit une chaîne en une clé de tri:
function icu_sort_key(string text [, icu_collation text]) returns bytea
C’est la même clé de tri que celle utilisée implicitement par Postgres pour créer des index impliquant des collations ICU.
La promesse de la clé de tri est que, si icu_compare(s1, s2, collator) renvoie X,
alors la comparaison (plus rapide) au niveau octet entre icu_sort_key(s1, collator) et
icu_sort_key(s2, collator) renvoie X également.
La documentation ICU prévient que le calcul d’une clé de tri est susceptible d’être nettement plus lent que de faire une seule comparaison avec la même collation. Mais dans le contexte d’un ORDER BY sur des requêtes et pour autant que mes tests soient représentatifs, c’est plutôt très rapide.
Du reste, en comparant les performances de ORDER BY field COLLATE "icu-coll" par
rapport à
ORDER BY icu_sort_key(field, 'collation'), la plus grande part de la différence
est causée par le fait qu’ icu_sort_key doive analyser la spécification
de la collation à chaque appel, et cette différence semble d’autant plus
grande que la spécification est complexe.
Tout comme pour icu_compare(), pour bénéficier du fait que Postgres
garde ouvertes les collations ICU pour la durée de la session,
il est recommandé d’utiliser la forme à un seul argument,
qui s’appuie sur sa collation, par exemple avec notre
“fr-ci” définie précédemment:
=# SELECT icu_sort_key ('Eté' COLLATE "fr-ci")
Toujours sur les performances, voici une comparaison d’EXPLAIN ANALYZE pour
trier 6,6 million de mots courts (de 13 caractères en moyenne) avec
icu_sort_key versus ORDER BY directement sur le champ:
ml=# explain analyze select wordtext from words order by icu_sort_key(wordtext collate "frci");
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------
Gather Merge (cost=371515.53..1015224.24 rows=5517118 width=46) (actual time=3289.004..5845.748 rows=6621524 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=370515.51..377411.90 rows=2758559 width=46) (actual time=3274.132..3581.209 rows=2207175 loops=3)
Sort Key: (icu_sort_key((wordtext)::text))
Sort Method: quicksort Memory: 229038kB
-> Parallel Seq Scan on words (cost=0.00..75411.99 rows=2758559 width=46) (actual time=13.361..1877.528 rows=2207175 loops=3)
Planning time: 0.105 ms
Execution time: 6165.902 msml=# explain analyze select wordtext from words order by wordtext collate "frci";
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------
Gather Merge (cost=553195.63..1196904.34 rows=5517118 width=132) (actual time=2490.891..6231.454 rows=6621524 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=552195.61..559092.01 rows=2758559 width=132) (actual time=2485.254..2784.511 rows=2207175 loops=3)
Sort Key: wordtext COLLATE frci
Sort Method: quicksort Memory: 231433kB
-> Parallel Seq Scan on words (cost=0.00..68515.59 rows=2758559 width=132) (actual time=0.023..275.519 rows=2207175 loops=3)
Planning time: 0.701 ms
Execution time: 6565.687 msOn peut voir ici qu’il n’y a pas de dégradation notable des performances
lors de l’appel de icu_sort_key explicitement. En fait, dans cet exemple c’est
même un peu plus rapide, sans que je sache vraiment pourquoi.
GROUP BY et DISTINCT ON peuvent aussi utiliser des clés de tri:
=# select count(distinct title) from books;
count
-------
2402
=# select count(distinct icu_sort_key(title)) from books;
count
-------
2360Utiliser des clés de tri dans les index
La position post-tri ou l’unicité d’un texte sous une certaine
collation équivaut à la position post-tri ou l’unicité de la clé binaire
correspondante dans cette collation.
Par conséquent il est possible de créer un index, y compris pour appliquer
une contrainte unique, sur icu_sort_key(column) ou icu_sort_key(column, collator)
plutôt que simplement column, pour contourner le problème
de la règle Postgres “pas d’égalité si la représentation binaire est différente”.
En reprenant l’exemple précédent avec la table books, on pourrait faire:
=# CREATE INDEX ON books (icu_sort_key(title));
pour qu’ensuite cet index soit utilisé pour des recherches exactes avec une requête comme suit:
=# SELECT title FROM books WHERE
icu_sort_key(title) = icu_sort_key('cortege' collate "mycoll");
title
---------
Cortège
CORTÈGE
Juste pour tester que l’index est effectivement utilisé:
=# explain select title from books where icu_sort_key(title)=icu_sort_key('cortege' collate "mycoll");
QUERY PLAN
-------------------------------------------------------------------------------------
Bitmap Heap Scan on books (cost=4.30..10.64 rows=2 width=29)
Recheck Cond: (icu_sort_key(title) = '\x2d454b4f313531'::bytea)
-> Bitmap Index Scan on books_icu_sort_key_idx (cost=0.00..4.29 rows=2 width=0)
Index Cond: (icu_sort_key(title) = '\x2d454b4f313531'::bytea)
Inspecter des collations
Comme mentionné plus haut, quand on se réfère à une collation par son identifiant ICU, les anciennes versions d’ICU ne comprennent pas la syntaxe plus moderne des tags BCP-47, ce qui ne se traduit pas nécessairement par une erreur, ils sont simplement ignorés.
Pour s’assurer qu’une collation est correctement nommée ou qu’elle
a les caractéristiques attendues, on peut contrôler la sortie de
icu_collation_attributes().
Cette fonction prend un nom de collation ICU en entrée,
récupère ses propriétés et les renvoie en tant qu’ensemble
de couples (attribute, value) comprenant son nom “affichable”
(displayname, probablement l’attribut le plus intéressant),
plus les tags kn / kb / kk / ka / ks / kf / kc correspondant à ses
caractéristiques, et enfin la version de la collation.
Exemple:
postgres=# select * from icu_collation_attributes('en-u-ks-identic');
attribute | value
-------------+---------------------------------
displayname | anglais (colstrength=identical)
kn | false
kb | false
kk | false
ka | noignore
ks | identic
kf | false
kc | false
version | 153.80
(9 rows)
-- Ci-dessus le displayname est en français, mais
-- on pourait le demander par exemple en japonais:
postgres=# select icu_set_default_locale('ja');
icu_set_default_locale
------------------------
ja
(1 row)
-- à noter le changement dans displayname
postgres=# select * from icu_collation_attributes('en-u-ks-identic');
attribute | value
-------------+------------------------------
displayname | 英語 (colstrength=identical)
kn | false
kb | false
kk | false
ka | noignore
ks | identic
kf | false
kc | false
version | 153.80
(9 rows)Autres fonctions
Au-delà des comparaisons de chaînes et des clés de tri, icu_ext
implémente des accesseur SQL à d’autres fonctionnalités d’ICU:
(voir le README.md
des sources pour les exemples d’appels aux fonctions):
-
icu_{character,word,line,sentence}_boundaries
Découpe un texte selon ses constituants et renvoie les morceaux en type SETOF text. En gros c’estregexp_split_to_table(string, regexp)en mieux dans le sens où sont utilisées les règles linguistiques recommandées par la standard Unicode, au lieu de simplement repérer les séparateurs sur la base d’expressions rationnelles. -
icu_char_name
Renvoie le nom Unicode de tout caractère (fonctionne avec les 130K+ du jeu complet). -
icu_confusable_strings_check and icu_spoof_check
Indique si un couple de chaînes est similaire, visuellement et si une chaîne comprend des caractères qui prêtent à confusion (spoofing). -
icu_locales_list
Sort la liste des toutes les locales avec les langues et pays associés, exprimés dans la langue en cours. Accessoirement, ça permet d’obtenir les noms de pays et de langues traduits en plein de langues (utilisericu_set_default_locale()pour changer de langue). -
icu_number_spellout
Exprime un nombre en version textuelle dans la langue en cours. -
icu_transforms_list et icu_transform
Applique des translitération (conversions entre écritures) et autres transformations complexes de texte. Il y a plus de 600 transformations de base listées par icu_transforms_list et elles peuvent combinées ensemble et avec des filtres. Voir la démo en ligne de ce service.
D’autres fonctions devraient être ajoutées dans le futur à
icu_ext,
ainsi que d’autres exemples d’utilisation des fonctions existantes.
En attendant n’hésitez pas à proposer des changements sur github
pour faire évoluer ces fonctions, ou exposer d’autres services
ICU en SQL, ou encore exposer différemment ceux qui le sont déjà,
ou bien entendu signaler des bugs…