On analyse la nouvelle collation de PostgreSQL 17
PostgreSQL 17 est sorti en version bêta le 23 mai dernier, et dans ce billet on va détailler une de ses nouveautés: une collation interne gérant l’UTF-8 avec des comparaisons de texte en binaire.
Un troisième fournisseur de collations
Jusqu’à présent on avait le choix entre deux fournisseurs (“providers”): la bibliothèque libc, qui est liée au système d’exploitation, et la bibliothèque optionnelle ICU. La version 17 en ajoute un troisième: “built-in”, pour des collations implémentées en interne dans le code source de Postgres.
La mention dans l’annonce en anglais nous dit:
PostgreSQL 17 includes a built-in collation provider that provides similar sorting semantics to the C collation except with UTF-8 encoding rather than SQL_ASCII. This new collation is guaranteed to be immutable, ensuring that the return values of your sorts won’t change regardless of what system your PostgreSQL installation runs on.
Il y a deux collations associées à “built-in”, toutes deux prévues pour l’encodage UTF8.
SELECT
collnamespace::regnamespace,
collname,
pg_encoding_to_char(collencoding) as encodage
FROM pg_collation WHERE collprovider='b'; -- 'b' = 'built-in'
collnamespace | collname | encodage
---------------+-----------+----------
pg_catalog | ucs_basic | UTF8
pg_catalog | pg_c_utf8 | UTF8
ucs_basic existait déjà dans les versions précédentes avec le fournisseur “libc”,
et a un comportement identique à la collation “C”. Quel est ce comportement?
Pour les comparaisons
de chaînes, elles se font en binaire, octet par octet, sans considération linguistique.
Pour la classification des caractères (c.a.d les questions de savoir si tel
caractère est une lettre,
une minuscule, une majuscule etc.) elle répond suivant une
table interne
pour tout caractère de code inférieur à 127 (aussi appelés SQL_ASCII dans l’annonce
ci-dessus),
et elle répond NON pour tout autre caractère,
quelle que soit la question. Evidemment ce n’est pas satisfaisant pour du texte Unicode.
Justement la nouvelle collation pg_c_utf8 résout ce problème
en répondant correctement pour
tout le répertoire Unicode, soit plus de 130000 codes. Elle permet donc
les opérations de mise en majuscule/minuscule et les expressions régulières
sur tous les alphabets. Certes, les autres fournisseurs libc et ICU permettent
aussi ça et depuis longtemps, mais en impliquant d’autres caractéristiques parfois
non souhaitables, résumées dans le tableau ci-dessous:
| Collation “C” ou ucs_basic |
Collations libc hors “C” |
Collations ICU | pg_c_utf8 | |
|---|---|---|---|---|
| Portabilité inter-système? | ✅ Oui | ❌ Non | ✅ Oui | ✅ Oui |
| Tri binaire? | ✅ Oui | ❓ Parfois | ❌ Non | ✅ Oui |
| M.a.j. système transparente? | ✅ Oui | ❌ Non | ❌ Non | ✅ Oui |
| Classification Unicode? | ❌ Non | ✅ Oui | ✅ Oui | ✅ Oui |
| Tri linguistique? | ❌ Non | ✅ Oui | ✅ Oui | ❌ Non |
| Comparaisons avancées? | ❌ Non | ❌ Non | ✅ Oui | ❌ Non |
Pour utiliser cette collation par défaut en création de base ou création d’instance,
il faut spécifier le nom de locale C.UTF-8 avec le fournisseur "built-in"
(attention à ne pas confondre avec les locales C.UTF-8 ou C.utf8 de certaines libc).
Par exemple:
initdb --locale-provider=builtin --locale=C.UTF8 -D /usr/local/pgsql/data
Quand l’instance n’utilise pas le fournisseur “built-in”, on peut créer une base avec ce fournisseur via une commande de ce type:
CREATE DATABASE test locale_provider='builtin' builtin_locale='C.UTF8' template='template0';
Et pour les bases qui n’utilisent pas ce fournisseur, on peut ajouter des clauses COLLATE pg_c_utf8
distillées dans les ordres SQL sur des colonnes ou des expressions.
Le tri binaire, avantages et inconvénients
On voit dans le tableau ci-dessus que les collations internes font du tri binaire alors que les collations
ICU n’en font pas. Pour libc ça dépend.
Par exemple avec Linux c’est seulement à partir de la version
2.35 de la libc GNU que la locale C.UTF-8 a cette fonctionnalité. Avec
FreeBSD c’est le cas également (j’ignore depuis quand). Avec Windows, il n’y a
pas à ma connaissance de locale Unicode équivalente.
C’est pourquoi il y a “❓ Parfois” dans cette case du tableau.
Rapidité d’indexation et de recherche
Le premier avantage des comparaisons binaires est qu’elles sont plus
économes que les comparaisons linguistiques en temps CPU.
Pour illustrer ça, considérons une table
de Internet Movie Database:
name_basics avec environ 13 millions de lignes.
La colonne primaryName, qui contient le nom des personnes intervenant sur les films,
avec environ 10 millions de valeurs distinctes, est un bon candidat pour tester
différentes collations.
Table « public.name_basics »
Colonne | Type |
-------------------+----------------------+
sn_soundex | character varying(5) |
deathYear | integer |
primaryProfession | text |
nconst | integer |
primaryName | text |
birthYear | integer |
s_soundex | character varying(5) |
ns_soundex | character varying(5) |
knownForTitles | text |
Dans une base créée avec la locale fr_FR.UTF-8 par défaut du système
(Linux Debian 12, avec GNU libc 2.36 et ICU 72).
On va créer des index avec différentes collations sur primaryName,
par exemple:
CREATE INDEX idx_pg_utf8 ON name_basics
USING btree("primaryName" COLLATE pg_c_utf8);
Déjà on voit des différences importantes sur les temps de création d’index.
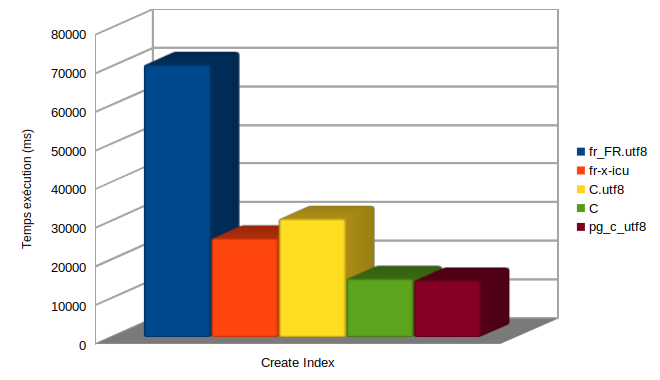
Ces différences se retrouvent aussi au moment des parcours d’index. Faisons un test
avec des requêtes qui recherchent quelques milliers de valeurs à chaque fois.
Ici on cherche simultanément toutes les valeurs du tableau arr, qui est un échantillon aléatoire de 0.02%
de la table (environ 2700 valeurs).
start := clock_timestamp();
for n in 1..1000
loop
SELECT count(*) into total FROM name_basics
WHERE "primaryName" COLLATE pg_c_utf8 = ANY(arr) ;
end loop;
raise notice 'Execution time: %', clock_timestamp()-start;
Si on essaye successivement avec nos différentes collations candidates, on obtient les résultats suivants:
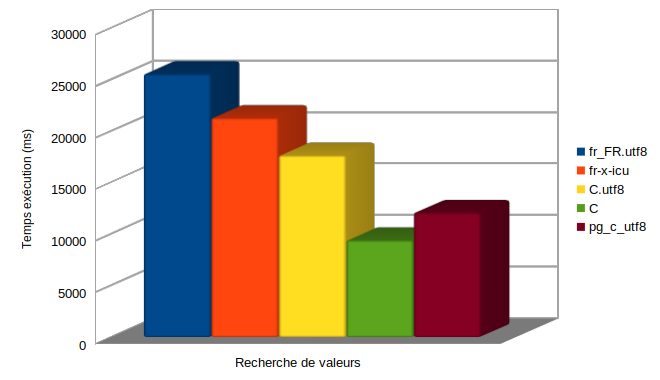
On voit que la nouvelle collation pg_c_utf8 est deux fois plus rapide que la collation par défaut fr_FR.UTF8.
Or pour répondre à la question “une valeur est-elle dans la table?”,
utiliser la collation linguistique fr_FR.UTF8 n’apporte aucune valeur ajoutée.
La comparaison linguistique est utile quand on veut savoir si une valeur est
avant ou après une autre dans un ordre de type dictionnaire.
Ordonnancement des résultats
Concrètement, supposons qu’on veuille sortir tous les primaryName qui commençent par “Adèle” ou “Adele”, dans une liste triée. On va faire une requête de ce type:
SELECT DISTINCT "primaryName" FROM name_basics
WHERE "primaryName" ~ '^Adèle' OR "primaryName" ~ '^Adele'
ORDER BY "primaryName" ;
Si la collation pg_c_utf8 est associée à la colonne, le résultat sort comme suit:
primaryName
------------------------------
Adele
Adele & The French StarKids
Adele Aalto
Adele Abbott
Adele Abinante
[...]
Adèle de Fontbrune
Adèle de Mesnard
Adèle de la Fuente
Adèle van Biljon
Adèle-Elise Prévost
(1342 lignes)
C’est-à-dire que tous les “Adele” sont regroupés dans une 1ère partie
de la liste, et tous les “Adèle” sont regroupés dans une 2ème partie.
C’est dû au fait que le point de code de la lettre è (U+00E8) est supérieur au code
de la lettre e (U+00065).
Si en revanche une collation linguistique est associée à la colonne, par exemple
fr_FR.utf8, le résultat va sortir comme suit:
primaryName
------------------------------
Adele
Adèle
Adele Aalto
Adele Abbott
Adele Abinante
Adele Abou Ali
Adele Aburrow
Adele Adams
Adele Adderley
Adele Addison
Adele Addo
Adele Adeshayo
Adele Adkins
Adèle Ado
[...]
Adele Zeiner
Adele Zin
Adele Zoppis
Adèle Zouane
Adele Zupicic
(1342 lignes)
A contrario de la liste précédente, les lettres e accentuées et non accentuées
au niveau du 3ème caractère
ne sont plus dans des groupes séparés, et le classement se trouve
principalement dirigé par le nom de famille. C’est l’ordre le plus
logique pour un observateur humain.
Pour bénéficier de ce tri préférable alors que la collation associée à la colonne
est pg_c_utf8, on peut ajouter des clauses COLLATE dans la requête.
On a à mon sens trois types de choix possibles:
-
soit écrire
"primaryName" COLLATE "fr_FR.utf8", qui ne fonctionnera que s’il y a une collation nomméefr_FR.utf8dans l’instance. Ca dépend du système et de l’installation donc pas portable. Et bien sûr, ça force un couple région/langue particulier. -
soit écrire
"primaryName" COLLATE "fr-x-icu". Toute instance de Postgres compilée avec ICU aura cette collation, ce qui en fait un choix quasi-portable. En revanche cela impose une langue particulière, ce qui n’est pas forcément voulu par l’application. -
soit écrire
"primaryName" COLLATE "unicode", qui existe depuis Postgres 16 et désigne la collation “root” d’ICU qui est linguistique mais sans règle liée à une langue en particulier. Avec Postgres 15 et antérieur, on peut aussi utiliser le moins mémorable"und-x-icu"à la place de"unicode".
En réalité beaucoup d’applications clientes trient de leur côté en fonction de la langue de l’utilisateur, qui n’est pas injectée dans les requêtes, et ne correspond pas spécialement à la collation par défaut de la base. En fait elles ignorent l’ordre de la base, et n’utilisent pas non de clause COLLATE explicite dans leurs requêtes.
Par exemple une application Javascript moderne pourra utiliser Navigator.language et Intl.Collator pour trier
des résultats en fonction de la langue du navigateur. Ce sera plus précis et plus simple
que d’interpréter la langue du navigateur, la transformer en un nom de collation
en étant assuré que cette collation existe dans la base, et l’injecter dans la requête SQL.
Dans ce type d’usage, le coût supplémentaire en temps CPU d’une collation linguistique
par rapport à la collation binaire pg_c_utf8 ne sert à rien.
Dans le cas où l’application compte sur le moteur SQL pour trier, il n’y a que dans des cas bien spécifiques qu’un index btree avec une collation linguistique va permettre des performances qu’on n’aurait pas autrement. Par exemple, l’extraction de toutes les valeurs entre deux bornes connues, dans un ordre du dictionnaire, sur une table de grande taille. Pour des applications qui ont ces besoins, on peut créer un index dédié avec une clause COLLATE explicite dans l’expression de l’index, du style:
CREATE INDEX idx_pg_utf8 ON name_basics
USING btree("primaryName" COLLATE "fr-FR.UTF-8");
ou encore pour avoir la collation linguistique générique:
CREATE INDEX idx_pg_utf8 ON name_basics
USING btree("primaryName" COLLATE "unicode");
Cet index assurera les mêmes
performances sur une extraction triée par ordre linguistique,
dans la mesure où la requête se réfère à la colonne via
"primaryName" COLLATE "unicode" au lieu de "primaryName" tout seul.
Index dédiés à certaines recherches
Le concept d’un index dédié à un certain type d’extraction existe d’ailleurs
déjà sur les recherches de type column LIKE 'start%' ou column ~ '^start'.
La documentation de Postgres l’explique ainsi:
Les classes d’opérateurs text_pattern_ops, varchar_pattern_ops et bpchar_pattern_ops supportent les index B-tree sur les types text, varchar et char, respectivement. À la différence des classes d’opérateurs par défaut, les valeurs sont comparées strictement caractère par caractère plutôt que suivant les règles de tri spécifiques à la localisation. Cela rend ces index utilisables pour des requêtes qui effectuent des recherches sur des motifs (LIKE ou des expressions régulières POSIX) quand la base de données n’utilise pas la locale standard « C ». Par exemple, on peut indexer une colonne varchar comme ceci : CREATE INDEX test_index ON test_table (col varchar_pattern_ops);
Il faut ajouter à cela la nouveauté que pg_c_utf8 est directement utilisable pour ces recherches,
au même titre que la locale standard « C ».
Pour reprendre l’exemple précédent, avec un seulement un index linguistique sur
le champ "primaryName", pour la requête suivante:
EXPLAIN ANALYZE select distinct "primaryName" from name_basics
where "primaryName" ~ '^Adèle' or "primaryName" ~ '^Adele'
order by "primaryName";
on obtient ce plan d’exécution:
Unique (cost=243279.95..243541.75 rows=2174 width=14) (actual time=4354.978..4356.406 rows=1342 loops=1)
-> Gather Merge (cost=243279.95..243536.32 rows=2174 width=14) (actual time=4354.978..4356.212 rows=1398 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Unique (cost=242279.92..242285.36 rows=1087 width=14) (actual time=4346.459..4346.578 rows=466 loops=3)
-> Sort (cost=242279.92..242282.64 rows=1087 width=14) (actual time=4346.453..4346.482 rows=487 loops=3)
Sort Key: "primaryName"
Sort Method: quicksort Memory: 25kB
Worker 0: Sort Method: quicksort Memory: 25kB
Worker 1: Sort Method: quicksort Memory: 25kB
-> Parallel Seq Scan on name_basics (cost=0.00..242225.11 rows=1087 width=14) (actual time=9.747..4345.114 rows=487 loops=3)
Filter: (("primaryName" ~ '^Adèle'::text) OR ("primaryName" ~ '^Adele'::text))
Rows Removed by Filter: 4345599
Planning Time: 0.186 ms
Execution Time: 4356.494 ms
On a donc un scan séquentiel coûteux.
Le conseil donné dans la doc pour accélérer ce type de requête est de créer un second index
avec ("primaryName" varchar_pattern_ops) qui sera trié en binaire.
Mais en fait, si dès le départ l’index sur "primaryName" utilise la collation pg_c_utf8, ou que la base utilise cette collation par défaut, il n’est pas nécessaire de créer un second index.
Car on aura dans ce cas de figure ce plan d’exécution qui tire parti de l’index tout seul:
Unique (cost=162.45..175.49 rows=2607 width=14) (actual time=30.616..31.048 rows=1342 loops=1)
-> Sort (cost=162.45..168.97 rows=2608 width=14) (actual time=30.612..30.699 rows=1461 loops=1)
Sort Key: "primaryName"
Sort Method: quicksort Memory: 49kB
-> Bitmap Heap Scan on name_basics (cost=10.44..14.46 rows=2608 width=14) (actual time=0.571..26.297 rows=1461 loops=1)
Recheck Cond: (("primaryName" ~ '^Adèle'::text) OR ("primaryName" ~ '^Adele'::text))
Filter: (("primaryName" ~ '^Adèle'::text) OR ("primaryName" ~ '^Adele'::text))
Heap Blocks: exact=1451
-> BitmapOr (cost=10.44..10.44 rows=1 width=0) (actual time=0.356..0.357 rows=0 loops=1)
-> Bitmap Index Scan on idx (cost=0.00..4.57 rows=1 width=0) (actual time=0.126..0.127 rows=268 loops=1)
Index Cond: (("primaryName" >= 'Adèle'::text) AND ("primaryName" < 'Adèlf'::text))
-> Bitmap Index Scan on idx (cost=0.00..4.57 rows=1 width=0) (actual time=0.227..0.227 rows=1193 loops=1)
Index Cond: (("primaryName" >= 'Adele'::text) AND ("primaryName" < 'Adelf'::text))
Planning Time: 0.473 ms
Execution Time: 31.132 ms
Moralité: avec ce type de requête, une base qui utilise des index linguistiques sans avoir besoin de l’ordre linguistique est doublement perdante: non seulement les créations et parcours d’index vont moins vite qu’avec des tris binaires, mais en plus il faut créer un second index pour ces recherches avec un ancrage en début de chaîne.
Immuabilité des index
Un autre avantage du tri en binaire, et pas des moindres pour les index, est qu’il est totalement invariable, ou en terme Postgres “immutable”. Cela implique qu’une mise à jour du système d’exploitation (en pratique de la libc) ou de la bibliothèque ICU n’implique pas de réindexer par sécurité.
Le tri linguistique au contraire, est sujet à des variations pour deux raisons: d’abord de nouveaux codes de caractères sont ajoutés à chaque nouvelle version d’Unicode, et ensuite des règles de comparaison peuvent très bien changer dans le CLDR et/ou dans les libc. Il y a quelques années, un changement majeur dans les locales de GNU libc 2.28 avait induit des index corrompus, comme on l’avait évoqué dans un billet précédent: Attention à votre prochain upgrade de glibc.
Depuis la version 15, Postgres s’est en partie prémuni contre ça en affichant des avertissements lorsqu’il détecte ces changements de versions, mais cette gestion manuelle de l’upgrade des locales reste pénible.
Dans le cas où on utilise les collations pg_c_utf8 ou “C”,
il n’y a rien à réindexer.
La classification des caractères
Trier en binaire est déjà possible avec la collation “C”, donc ce n’est pas
une raison suffisante pour inventer pg_c_utf8. Comme dit plus haut,
la différence est que pg_c_utf8 intègre les données des fichiers
Unicode de l’Unicode Character Database
qui donne les caractéristiques de tous les points de code.
C’est ainsi qu’on a des résultats corrects pour toutes les opérations
impliquant la classification des caractères.
Par exemple:
| Opération | Collation “C” ou ucs_basic |
Collation pg_c_utf8 |
|---|---|---|
upper('élysée') |
éLYSéE | ÉLYSÉE |
lower('ÉLYSÉE') |
ÉlysÉe | élysée |
initcap('élysée') |
éLyséE | Élysée |
'été' ~ '^\w+$' |
false | true |
Un autre aspect important de pg_c_utf8 est la compatibilité entre
les différents systèmes d’exploitation.
Dans un autre billet (Classification des caractères avec ICU), on voyait des exemples d’expressions
donnant des résultats différents entre ICU et la libc, mais aussi entre différentes libc,
en comparant les libc de GNU, Windows 10, FreeBSD.
Sur cette question pg_c_utf8 ne s’aligne sur aucune de ces locales en particulier, mais
s’ajoute comme un choix supplémentaire. Mais il offre un avantage de portabilité
par rapport aux collations libc, dans le sens où
pour une version donnée de Postgres,
son comportement sur la classification sera identique sur toutes les plateformes.
En revanche, d’une version majeure à l’autre, Postgres suivra les
évolutions d’Unicode, et donc la collation pg_c_utf8 intégrera
tout changement induit par les fichiers de données de
l’Unicode Character Database. En pratique, ça concerne
surtout l’ajout de nouveaux caractères, notamment des emojis et des
langues anciennes.
Conclusion
La plupart des utilisateurs n’ont pas envie d’écrire des clauses COLLATE dans leurs requêtes ni de faire des choses compliquées avec les collations. Ils veulent que les opérations sur les chaînes de caractère fonctionnent efficacement et produisent des résultats corrects.
De ce point de vue, la logique de beaucoup de projets est de laisser la collation par défaut de la base, qui correspond généralement à une locale déduite du pays/langue de l’installation système, et de supposer que c’est le meilleur choix. Ca le mérite d’être simple, mais ça ne donne pas les meilleures performances, ni la meilleure expérience utilisateur lors des migrations système, ni la meilleure portabilité.
L’introduction de ce fournisseur “built-in” dans Postgres 17 permet de partir relativement simplement sur une collation par défaut plus performante. Pour ma part je trouve assez raisonnable, quand on démarre une base en UTF-8, d’appliquer la logique suivante:
- créer la base avec le fournisseur “built-in” par défaut.
- si et quand on a besoin de tri linguistique sur certaines requêtes,
ajouter
COLLATE "unicode"aux clausesORDER BY, voire à certains index si c’est pertinent.
En échange de cette concession sur les tris linguistiques, on obtient pour tout le reste:
- des index plus rapides.
- des index qui survivent sans danger aux migrations système.
- des comportements “classification des caractères” identiques sur toutes les plateformes.